문법
MLOps
- 해결 영역
- 데이터 준비 단계 : 적시에 고품질 데이터 제공
- ML Model 학습 단계 : 분석에 집중할 수 있는 환경 제공
- 모델 서비스 단계 : 비즈니스 가치에 집중할 수 있도록 함
- 모델 서빙
- 모델이 예측한 값을 사용자에게 전달
- 형상관리(모델 변경이력, 성능 관리)
- 고가용성/확장성 (장애와 유연함에 대응)
- ml flow
- 모델에 대한 실험과 버전을 트래킹하는 파이썬 app
- kube flow
- 쿠버네티스 클러스트 안에서 버전 관리
용어
-
data lake : 구조화되지 않거나 그에 준하는 대량의 데이터로 저장, 처리, 보호하기 위한 중앙 집중식 저장소
-
data warehouse : 트랜젝션 시스템, 운영 데이터베이스 및 애플리케이션의 관계형 데이터 중앙 레포지토리
-
data mart : 단일 주제 또는 LOB(사업부서)에 초점을 맞춘 단순한 형태의 데이터 웨어하우스
-
ML Pipeline : 데이터를 바탕으로 알고리즘을 넣으면 모델이 생성, 서비스 배포 과정에서 설정값이 넘어가고 라이브 데이터가 들어오면서 추론하게 됨
-
mldlow.artifactos/
- 실험 중에 생산된 산출물(모델, 데이터 파일, 이미지 등) 저장하는 폴더
-
inference 추론 : 모델 훈련 후, 새로운 데이터에 대해 모델을 사용하여 예측을 수행하는 과정 :: 예측 값은 모델이 학습한 패턴을 바탕으로 생성
-
prediction 예측 : 모델이 입력 데이터에 대해 생성한 출력값
-
ground truth 실제값 : 모델이 예측한 값과 비교하기 위한 참조 값
-
residual 잔차 : 예측 값과 실제 값의 차이
-
loss 손실 : 모델의 예측 값과 실제 값 사이의 차이를 측정하는 함수의 출력 :: 최적화의 기준
-
accuracy 정확도 : 모델의 예측이 얼마나 정확한지 나타내는 지표 (100의 테스트 데이터 중 90을 올바르게 분류했다면 90% 정확도)
-
precision 정밀도 : 모델이 양성으로 예측한 샘플 중 실제로 양성인 샘플의 비율 :: 불균형 데이터셋 용도
-
recall 재현율 : 실제 양성 샘플 중 모델이 올바르게 양성으로 예측한 샘플의 비율 :: 민감도
-
F1 Score F1점수 : 정밀도와 재현율의 조화 평균 : 불균형에 유용
-
confusion matrix 혼동행렬 : 분류 모델 성능을 시각적으로 나타내는 행렬
-
데이터 수집/전처리 > 데이터 분할(train/ test로 구분) > 하이퍼 파라미터 튜닝(테스트 결과가 만족스럽지 않을 경우 튜닝) > 추론(inference로 예측값 생성) > 모델 모니터링
반도체 용어
- TDK(Technology Development Kit)
- Lot Tracking : 생산 로드별 품질 및 공정 데이터 추적
- 데이터 소스 : 로드 ID, 공정 단계별 파라미터, 검사 결과
- 시각화 방법 : X축(공정 단계 또는 시간)과 Y축(주요 품질 지표)을 사용한 다중 라인 그래프
- wafer map : 웨이퍼 표면의 불량 분포를 시각화 한 2D 맵
- 데이터 수집 : 웨이퍼 이미지, 센서 데이터, 공정 파라미터
- 전처리 : MLFlow 파이프라인을 활용한 데이터 정체 및 특성 추출
- 모델 개발: AutoML(예: AutoGluon)을 활용한 초기 모델 생성
- 실험 관리 : MLFLow Tracking을 이용한 실험 결과 기록 및 비교
- 모델 배포 : MLFlow models를 활용한 모델 패키징 및 배포
- 모니터링 : Prometheus와 Grafana를 활용한 실시간 성능 모니터링
- MLFlow Tracking: 파라미터, 버전, 메트릭 등을 기록하고 비교
- MLFlow Projects : 재현 가능한 실행을 위한 표준 형식
- MLFlow Models : 다양한 환경에서 모델을 배포하기 위한 표준 형식
- MLFlow Registry : 모델의 전체 수명 주기를 관리하는 중앙 모델 저장소
- MLFlow 흐름
- 실험 추적 : ‘mlflow.start_run()’을 사용하여 실험 시작
- 파라미터 및 메트릭 로깅: ‘mlflow.log_param()’, ‘mlflow.log_metric()’ 사용
- 모델 저장 : ’mlflow.sklearn.log_model()’ 등을 사용하여 모델 아티팩트 저장
- 실험 비교: MLFlow UI를 통해 여러 실험 결과 비교
- 모델 배포 : MLFlow Models를 사용하여 다양한 환경에 모델 배포
- numeric/ image 정보 분석에 관한 반도체 공정 내용
- 웨이퍼 맵 분석기 : CNN 기반 이미지 분석
- 시계열 이상 감지기 : LSTM을 활용한 센서 데이터 분석
- 공정 파라미터 최적화기 : 강화학습 기반 파라미터 조정
- MTS : Multivariate Time Series Output은 여러 공정 변수의 시간에 따른 변화를 동시에 시각화
- 데이터 소스 : 실시간 공정 모니터링 데이터, 센서 측정값
- 특정 웨이퍼마다 inference 값과 실제 값의 비교
구조 (kubeflow)
구조 (ml flow)
- tracking
- mlflow ui —port 5000 : source 모델 tracking한 정보 출력
from mlflow import log_metric, log_param, log_artifacts
# 이하 코드
- serving model
- python project/<PROJECT_PATH>/train.py
- mlflow models serve —mldel-uri runs:/<MODEL_SAVE_ID>/model
- project from a url
- mlflow run project<PROJECT_PATH> -P alpha=0.4
MLOps(ML Operations)은 머신러닝 모델의 개발, 배포, 운영을 효율적으로 관리하는 방법론입니다. MLOps에서 중요한 요소들은 다음과 같습니다:
-
자동화(Automation):
- CI/CD 파이프라인: 코드 변경이 자동으로 테스트되고 배포되는 지속적 통합(CI)과 지속적 배포(CD) 파이프라인을 구축합니다.
- 모델 훈련 및 배포 자동화: 모델 훈련과 배포 과정을 자동화하여 일관성과 신뢰성을 높입니다.
-
데이터 관리(Data Management):
- 데이터 버전 관리: 데이터 세트의 버전을 관리하여 재현 가능성을 보장합니다.
- 데이터 품질 모니터링: 데이터의 품질을 지속적으로 모니터링하고 데이터 드리프트를 감지합니다.
-
모니터링 및 관찰성(Monitoring and Observability):
- 모델 성능 모니터링: 배포된 모델의 성능을 지속적으로 모니터링하여 성능 저하를 빠르게 감지합니다.
- 로그 및 메트릭 수집: 로그와 메트릭을 수집하여 시스템 상태를 분석하고 문제를 진단합니다.
-
협업 및 커뮤니케이션(Collaboration and Communication):
- 팀 협업 도구: 개발자, 데이터 과학자, 운영 팀 간의 원활한 협업을 위한 도구와 프로세스를 마련합니다.
- 명확한 문서화: 프로세스와 모델에 대한 명확한 문서를 작성하여 지식 공유와 유지보수를 용이하게 합니다.
-
보안(Security):
- 데이터 보안: 민감한 데이터의 접근 권한을 관리하고 보안 규정을 준수합니다.
- 모델 보안: 모델이 악용되지 않도록 보안 조치를 취합니다.
-
확장성(Scalability):
- 확장 가능한 인프라: 수요 증가에 따라 시스템을 확장할 수 있는 인프라를 구축합니다.
- 탄력적인 리소스 관리: 클라우드나 컨테이너 기술을 활용하여 리소스를 효율적으로 관리합니다.
-
재현성(Reproducibility):
- 실험 추적 및 관리: 실험 결과와 하이퍼파라미터를 추적하여 실험의 재현성을 보장합니다.
- 환경 관리: 개발 환경과 배포 환경을 일치시켜 예측 가능한 결과를 제공합니다.
MLOps는 데이터 과학, 소프트웨어 엔지니어링, DevOps의 교차점에 위치하며, 위의 요소들을 종합적으로 관리함으로써 머신러닝 프로젝트의 성공을 도모합니다.
2. 데이터 관리
데이터 관리는 MLOps에서 매우 중요한 요소로, 데이터의 품질, 버전 관리, 보안 등을 포함합니다. 다음은 데이터 관리의 주요 구성 요소와 예시입니다.
1. 데이터 버전 관리(Data Versioning)
설명:
데이터 버전 관리는 데이터를 시간에 따라 다른 버전으로 관리하는 것입니다. 이를 통해 언제든지 특정 시점의 데이터로 돌아가거나, 데이터 변경의 이력을 추적할 수 있습니다.
예시:
예를 들어, 한 회사가 고객의 구매 데이터를 기반으로 예측 모델을 개발한다고 가정해보겠습니다. 이 회사는 데이터 버전 관리 시스템을 사용하여 2023년 1월 데이터 버전을 v1으로, 2023년 2월 데이터를 v2로 관리할 수 있습니다. 만약 모델이 특정 시점 이후로 성능이 저하되면, 이전 데이터 버전으로 돌아가서 원인을 분석할 수 있습니다.
2. 데이터 품질 관리(Data Quality Management)
설명:
데이터 품질 관리는 데이터의 정확성, 완전성, 일관성 등을 보장하기 위한 프로세스를 의미합니다. 데이터 품질이 떨어지면 모델의 성능도 저하되므로 중요한 요소입니다.
예시:
한 금융 기관에서 신용 점수 예측 모델을 만들기 위해 데이터를 수집한다고 가정해봅시다. 이 과정에서 누락된 값, 중복된 데이터, 이상치 등을 제거하여 데이터 품질을 개선할 수 있습니다. 예를 들어, 결측치를 평균값이나 중앙값으로 대체하고, 데이터의 일관성을 유지하기 위해 형식을 통일합니다.
3. 데이터 보안(Data Security)
설명:
데이터 보안은 민감한 데이터를 보호하고, 무단 접근이나 유출을 방지하는 것을 의미합니다. 이는 개인정보 보호법 등을 준수하는 데 필수적입니다.
예시:
의료 기관에서 환자의 의료 기록을 다루는 경우, 데이터는 암호화되어야 하고 접근 권한이 있는 사용자만 접근할 수 있도록 설정해야 합니다. 또한, 데이터 접근 로그를 기록하여 누가 언제 어떤 데이터에 접근했는지 추적할 수 있습니다.
4. 데이터 수명 주기 관리(Data Lifecycle Management)
설명:
데이터 수명 주기 관리는 데이터 생성부터 폐기까지의 전체 과정을 체계적으로 관리하는 것을 의미합니다.
예시:
전자 상거래 회사에서 고객 데이터를 생성, 사용, 보관, 폐기하는 과정을 관리한다고 가정해봅시다. 데이터 생성 단계에서는 새로운 고객 정보를 수집하고, 사용 단계에서는 이를 분석하여 마케팅 전략을 세우며, 보관 단계에서는 일정 기간 동안 안전하게 보관한 후, 폐기 단계에서는 법적 요구사항에 따라 데이터를 안전하게 삭제합니다.
5. 데이터 통합 및 관리(Data Integration and Management)
설명:
데이터 통합은 다양한 소스에서 데이터를 수집하고 이를 일관성 있게 결합하여 관리하는 것을 의미합니다.
예시:
한 제조업체에서 생산 라인, 재고 관리 시스템, 판매 시스템 등 여러 소스에서 데이터를 수집한다고 가정해보겠습니다. 이 데이터를 통합하여 생산 효율성을 분석하고, 재고 최적화 및 판매 예측을 위한 모델을 개발할 수 있습니다. 이를 위해 ETL(Extract, Transform, Load) 도구를 사용하여 데이터를 추출하고, 변환하여, 적절한 저장소에 로드합니다.
이와 같은 데이터 관리는 머신러닝 프로젝트의 성공에 중요한 역할을 하며, 이를 통해 보다 신뢰할 수 있는 모델을 구축하고 유지할 수 있습니다.
노드추가와 연동 예시
- manage > Create > Create Custom
- TLS 해제한 클립보드를 work node shell에서 실행
- rebort 하거나 etcd/Control Plane 먼저 구성하기
- 참고 : https://kusmile.medium.com/rancher-chapter-2-cluster-생성하기-83f9b1d01087
rancher 설치
- docker 설치
- rancher dockerfile 생성
version: '3'
services:
rancher:
image: rancher/rancher:latest
restart: always
ports:
- "22080:80/tcp"
- "22443:443/tcp"
volumes:
- "rancher-data:/var/lib/rancher"
privileged: true
volumes:
rancher-data:
MSA transaction
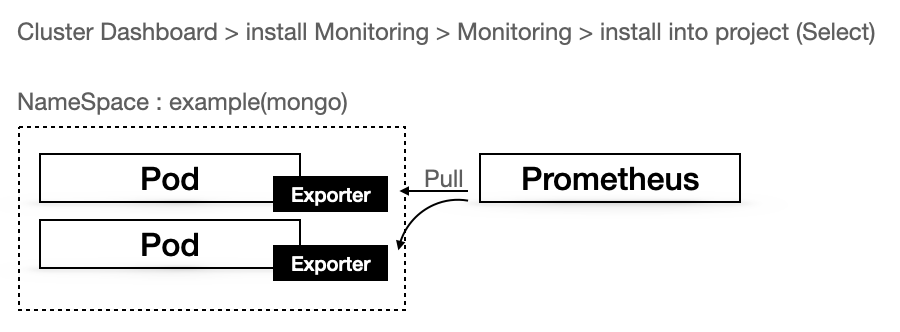
prometheus
명령어
- node 목록 확인
kubectl get node -o=wide
kubectl describe node <NODE_NAME>
- pod 목록 확인
kubectl get pod -n <NAMESPACE>
kubectl describe pod <POD_NAME>
- pod 삭제
- kubectl delete pod <POD_NAME>
- kubectl delete pod —selector=<LABEL_KEY>=<LABEL_VALUE>
- pod 접속
- kubectl exec <POD_NAME> -it — bash
- 예: kubectl exec -ti mongodb-1 -n mongodb — /bin/bash
- replicaset 조회
- kubectl get replicaset
- replicaset 삭제
- kubectl delete replicaset <REPLICASET_NAME>
- deployment 조회
kubectl get deploy
kubectl get deployment
kubectl get deployreplicaset,pod
- deployment 재배포
- rollingUPdate : 새 버전을 배포하면서 무중단 배포
- recreate : 기존 pod삭제 후 생성
- canary : 분산 테스트 후 서서히 옮겨가는 방법
kubectl rollout status deployment <DEPLOYMENT_NAME>
kubectl rollout history deployment <DEPLOYMENT_NAME>
kubectl rollout restart deployment <DEPLOYMENT_NAME>
- deployment 삭제
- kubectl delete deploy <DEPLOY_NAME>
- service 목록 확인
kubectl get svc
kubectl get svc -n NAME_SPACE
kubectl describe svc -n NAME_SPACE
kubectl get service
-
service 삭제
- kubectl delete service <SERVICE_NAME>
-
kube ingress 정보 출력
Kubectl get ing -n hcms-dev
Kubectl describe ingress -n hcms-dev
- manifest 반영 명령어
- kubectl apply -f <MANIFEST_FILE>
- 삭제 명령어
- kubectl delete -f <MANIFEST_FILE>
- rollout 성공 확인 명렁ㅇ
- kubectl rollout status deploy <DEPLOY_NAME>
- revision 목록 확인 명렁어
- kubectl rollout history deploy <DEPLOY_NAME>
- revision별 변경사항 상세 확인 명령어
- kubectl rollout history deploy <DEPLOY_NAME> —revision=<revision_value>
- deploy 현재 revision 상태 확인 명렁
- kubectl desctibe deploy <DEPLOY_NAME> | grep revision
- event log확인
- kubectl get event -w #-w : 변경사항이 있을 경우 실시간으로 로그 출력
- pod log 확인
- kubectl logs <POD_NAME>
- pod 접속
- kubectl exec -it <POD_NAME> bash
- pod에서 shwll 명령어 실행\
- kubectl exec -it <POD_NAME> curl 192.168.0.1
- pod를 임시로 띄어 명령어 실행 후 pod삭제
- kubectl run -it test-pod —image=busybox —rm restart=Never —command — ls -al
- kubectl run -it test-pod —image=byrnedo/alpine-curl —rm —restart=Never —command — curl 192.168.0.1
- pod끼리 통신 가능여부 확인
- kubectl exec -n hcms-dev -it hcms-gateway-2.0-fddffcdb8-s6tsf — nslookup 10.42.217.181
- Kubectl exec -n hcms-dev -it gateway2-6fdfbd877d-mcmfz — pring 10.42.217.181
- Kube pod에 접속하여 명령어 입력
- kubectl exec -n hcms-dev -it hcms-front-867b559844-5mbmb — npm run start
- curl 예제
- curl -X POST ‘http://<domain>.<namespace>:<port>/<path>’ -H “content-Type: application/json” -d ‘{}’
#### kubectl 설치
- https://kubernetes.io/ko/docs/tasks/tools/install-kubectl-windows/
#### helm 설치
- choco install kubernetes-helm
- Go templete 설치
#### config map 활용 (rancher ver)
- more resource > core > configmap
- Deployment.yaml
- env:
- Name: BACK_URL <app의 key (예) ${BACK_URL}>
valueFrom:
configMapKeyRef:
key: back-url <configMap의 key>
name : enviroment <configMap이름>
- Name: BACK_URL <app의 key (예) ${BACK_URL}>
docker 에 curl 추가 (apline ver)
- apk —no-cache add curl
pop끼리 통신 url
- serviceName.hcms-dev:port
- (예) http://hcms-mongo-management:80 :: nameSpace생략
- (예) http://hcms-mongo-management.hcms-dev:80
kube Account project 관리 (spaceOne cloudforet 기준)
- 하나의 AccountId는 하나의 Project를 갖고 있다. (AccountId (AccountName) > projectId)
- trustedAccount :
- generalAccount : 개별 암호화 키를 통해 어카운트를 직접 등록
- trustedAccount : generalAccount와 연결 가능한 trustedAccount생성